Published: Feb 25, 2024 by Luis Pastrana
Cómo hacer una Red Neuronal desde Cero usando Python
Código disponible en: pxstrana/neural-networks
Introducción
Hoy en día, las redes neuronales están en el centro de atención, especialmente los modelos “Transformers” como ChatGPT, Bard y Bing Copilot. Estos modelos están revolucionando el procesamiento del lenguaje natural, la generación de texto y multitud de otras tareas.
Este post surge de querer intentar realizar por mí mismo la programación de redes neuronales, para asentar mejor los conocimientos y, por otro lado, animar a más personas interesadas en el tema a intentarlo por sí mismas.
Las publicaciones que me han animado y me han servido como guía han sido:
A diferencia de las publicaciones anteriores, decidí aplicar un enfoque orientado a objetos, ya que resultaría más fácil de entender y más flexible a la hora de introducir cambios.
Estructura de la Red Neuronal
Conceptos básicos
Antes de adentrarnos en aspectos más técnicos, vamos a presentar una forma intuitiva de ver la Red Neuronal.
En la imagen a continuación, vemos un perceptrón, que es la representación simplificada de una neurona.
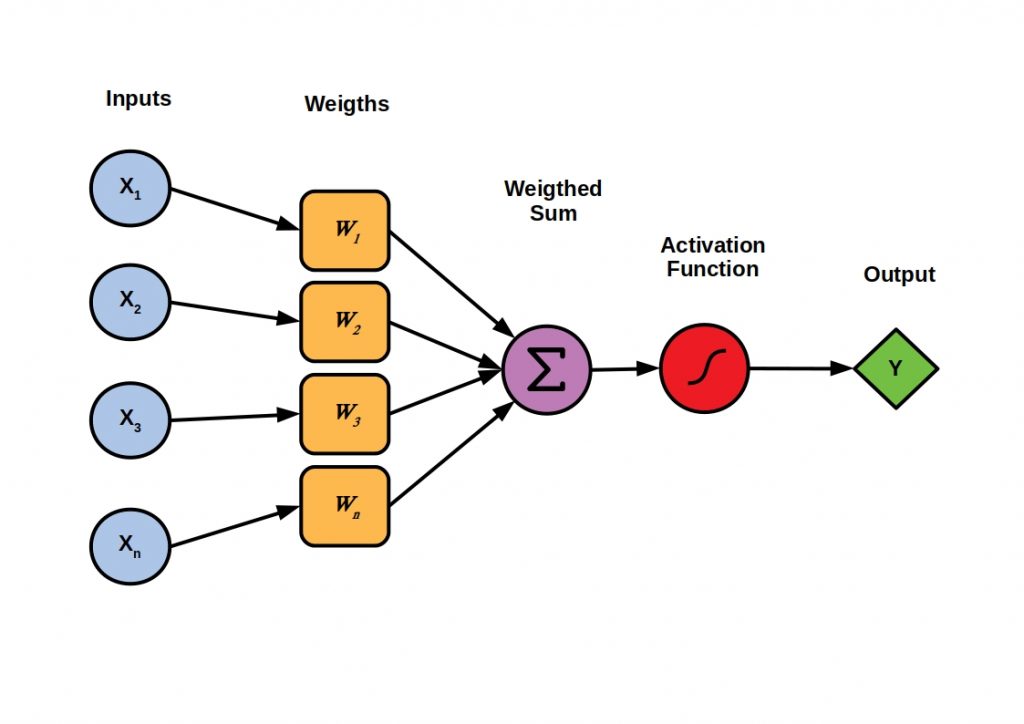
- Los Inputs son los valores que recibimos de entrada, es decir, la información con la que vamos a predecir.
- Los Weigths es la importancia que le da a cada Input.
- Posteriormente se realiza una suma ponderada de cada Input por su Weight.
- A esta agregación se le aplica una función de activación para convertirlo en el formato de salida adecuado, por ejemplo para obtener valores entre 0 y 1 (muy usado en probabilidades). También pueden ser de utilidad otros tipos, como ReLu y Softmax.
En una red neuronal, se concatenan cientos de neuronas, por lo que un Input puede provenir del Output de otra neurona. Esto es muy importante para entender la estructura que vamos a implementar.
Estructura a implementar
En nuestra estructura, vamos a llamar al elemento básico Nodo y todo nodo podrá hacer lo siguiente:
- Saber cuál es el valor de su salida.
- Realizar el proceso de backpropagation.
- Conectarse a otros nodos.
De esta forma, podremos tratar a cada nodo de la misma manera, aunque tengan comportamientos diferentes.
from abc import abstractmethod
class Node():
@abstractmethod
def get_output(self):
pass
@abstractmethod
def backpropagate(self):
pass
@abstractmethod
def connect_forward(self,output_node):
pass
Dentro de los nodos, distinguimos 2 tipos:
- Nodos valor (OnlyValueNode): Únicamente introducen la información al modelo.
- Perceptrones o neuronas (Neuron): Encargados del funcionamiento del modelo.
Con esta estructura, nos resultará muy sencillo aplicar la magia de las redes neuronales.
¿Cómo funcionan?
La clave de las redes neuronales radica en la capacidad de realizar ajustes muy precisos gracias a la combinación de neuronas. Sin embargo, estos ajustes no ocurren por arte de magia, estos requieren de un mecanismo que permita corregir los errores, llamado backpropagation.
Explicado de forma sencilla: una vez que el modelo realiza una predicción esta se compara con el resultado real, y como si fuese un entrenador, la última neurona corrige a aquellas que cree que estuvieron involucradas en hacer que el resultado fuese malo. Estas a su vez vuelven a hacer lo mismo hasta llegar a las iniciales.
Esto nos permite distinguir dos procesos:
- Feedforward: Realizar una predicción.
- Backpropagation: Corregir errores.
Clase Neurona
Debido a que las neuronas van a enviar datos hacia delante y hacia atrás, estas deben saber cuales son los nodos entrada y los nodos salida. Además de la información propia de un perceptrón: pesos para cada nodo de entrada, sesgos (no implementado por simplicidad), función de activación.
Relacionados con backpropagation consideraremos:
- La estimación del error que ha supuesto esa misma neurona, lo llamaremos delta.
- La derivada de la función de activación
class Neuron(Node):
def __init__(self, activation_function=sigmoid) -> None:
self.input_nodes = []
self.output_nodes = []
self.weights = []
self.activation_function = activation_function
self.deriv_activation_function = deriv_activation_functions.get(activation_function)
self.delta = None
def dot_product(self):
"""
Calculates the dot product of the inputs and weights.
"""
lista_input = [nodo.get_output() for nodo in self.input_nodes]
return np.dot(lista_input,self.weights)
def get_output(self):
"""
Calculates the output of the neuron using the activation function.
"""
return self.activation_function(self.dot_product())
def connect_forward(self, output_node):
"""
Connects the current node to a forward node.
Parameter:
output_node: The node to connect to.
Returns:
Node: Self node.
"""
self.output_nodes.append(output_node)
output_node.add_input_node(self)
return self
def add_input_node(self, node):
"""
Adds an input node to the neuron.
Parameter:
Node: The input node to add.
"""
self.input_nodes.append(node)
# Recalculate weights with mean=0 and std=1 when adding a node
self.weights= np.random.randn(len(self.input_nodes))
return self
def get_delta(self):
"""
Returns the delta value of the neuron, which is used in backpropagation.
"""
return self.delta
La asociación de los nodos de entrada con el peso se realiza a través del índice, existen mejores formas pero en esta versión por simplicidad sería suficiente.
Clase OnlyValueNode
Es una clase muy sencilla diseñada para representar los valores de entrada en la red neuronal. No realiza cálculos complejos, simplemente devuelve su valor y puede conectarse con otros nodos.
class OnlyValueNode(Node):
def __init__(self, input_value) -> None:
self.input_value = input_value
self.output_nodes = []
def get_output(self):
return self.input_value
def connect_forward(self, output_node):
self.output_nodes.append(output_node)
output_node.add_input_node(self)
return self
def backpropagate(self):
pass
FeedForward
Con lo visto en las clases anteriores ya podríamos hacer FeedForward, es decir realizar una predicción.
Para facilitar las conexiones vamos a crear un método auxiliar que conecte una lista de nodos de entrada con una lista neuronas (todos con todos).
def connect_layer_forward(input_nodes, neurons):
for input_node in input_nodes:
for neuron in neurons:
input_node.connect_forward(neuron)
Con el siguiente código podríamos probar que funciona el feedforward:
input_nodes = [OnlyValueNode(0),OnlyValueNode(1)]
# Correct result
output_dataset = [1]
# -----------FeedForward---------------
# Create a layer and connect it with inputs
layer_1 = [Neuron(),Neuron()]
connect_layer_forward(input_nodes,layer_1)
# Create 2nd layer and connect with the previous one
layer_2 = [Neuron()]
connect_layer_forward(layer_1,layer_2)
# Result of the neuron in the last layer
print(layer_2[0].get_output())
Backpropagating
Para entender esta parte mejor vamos a poner un ejemplo:
Imaginemos que hemos ido de excursión y tras subir a la cima de la montaña ha bajado la niebla y no sabemos que dirección seguir. Solo sabemos que tenemos que llegar al valle donde hemos aparcado el coche.
Si todo fuese sencillo, bajando la pendiente deberíamos llegar.
Este es el enfoque principal, aunque como podemos suponer posiblemente haya repechos y para llegar haya que subir y bajar varias veces. Esto supone el problema de mínimos locales.
Con esto en mente, necesitamos una forma de cuantificar el error (distancia al coche). Comúnmente se usa el error cuadrático medio (MSE).
\[MSE=\frac{1}{2n} \sum (y−y')^2\]- n: es el número de ejemplos, en nuestro caso 1.
- y: es el valor real.
- y’: es la predicción.
Esto nos daría un error tanto si estamos cerca del pico como si nos hemos pasado de largo. Así que para saber la dirección calcularemos la pendiente, esta es la derivada del MSE respecto a y’.
\[derivada(MSE)=\frac{1}{2} (-1* 2(y−y'))= -(y-y')=y'-y\]La pendiente además de indicar la dirección tiene un valor intuitivo, ya que es la propia diferencia. ¿Entonces, cuánto tenemos que corregir los valores de entrada para que cambie y’?
Pues debido a que a dichos valores se les aplica una función de activación y no tiene por qué ser lineal, no es lo mismo variar x en un punto u en otro. Por ejemplo para la función x^2: (2)^2= 4 y (2+1)^2 = 9, la diferencia en y, aumenta exponencialmente.
Esto lo resolvemos multiplicando por la derivada de la función de activación, ya que nos da la pendiente en ese punto.
Aun así, puede que nuestro modelo no se adapte bien y por ello se añade un optimizador al modelo llamado learning rate para aumentar o reducir la velocidad de aprendizaje (cambio en los pesos).
Esto se resume en: delta = (y’-y) * derivada_f_activacion(y’)
Este se usará para actualizar los pesos de la siguiente manera:
\[peso\_l=peso\_l−(learning\_rate∗output\_l−1∗delta\_l)\]Siendo \(l\), la capa en la que se encuentra la neurona.
Es decir, los pesos serán corregidos en función del error que haya cometido dicha neurona (delta) y la salida para la cual ese peso fue asignado. Si la salida es pequeña, no tuvo mucha implicación y por tanto su peso no cambiará mucho.
Debido a que este delta debe propagarse por toda la red, distinguimos 2 funciones:
- output_delta_function: Encargada de comparar con el valor final y crear el primer delta.
- hidden_delta_function: Encargada de propagar los deltas desde las neuronas finales hasta las iniciales.
Ambas utilizan el concepto de Error x Derivada de función de activación.
def output_delta_function(self,value):
"""
Calculates delta error for the output neuron: (prediction-value) * deriv_activation_function(prediction).
"""
deriv_cost_function = self.get_output() - value
self.delta = deriv_cost_function * self.deriv_activation_function(self.get_output())
return self.delta
def hidden_delta_function(self):
"""
Calculate the delta in a neuron, as the errors it propagates, using the formula: Summation( weight_forward * delta_forward) * deriv_activation_function(prediction).
"""
suma = 0
for node in self.output_nodes:
weight_forward = node.get_weight_of_node(self)
delta_forward = node.get_delta()
suma += (weight_forward * delta_forward)
self.delta = suma * self.deriv_activation_function(self.get_output())
return self.delta
def get_weight_of_node(self, node):
"""
Returns the weight between 2 nodes
"""
for i in range(len(self.input_nodes)):
if (self.input_nodes[i]==node):
return self.weights[i]
return None
Como mencionamos antes, una vez se calcula el delta, podemos recalcular los pesos:
def update_weights(self, learning_rate=0.1):
"""
Recalculates the weights using the following formula for the layer: weight = weight - (learning_rate * output_backward * delta)
"""
for i in range(len(self.input_nodes)):
self.weights[i] = self.weights[i] - (learning_rate* self.input_nodes[i].get_output()*self.delta)
En este momento, ya tenemos todo lo necesario para realizar backpropagation, así que crearemos una función que recursivamente vaya realizando el proceso.
def backpropagate(self, learning_rate=0.1):
"""
Performs the backpropagation process recursively down to the OnlyValueNode nodes.
"""
self.update_weights(learning_rate)
for input_node in self.input_nodes:
input_node.hidden_delta_function()
input_node.backpropagate()
Un ejemplo del código completo sería:
input_nodes = [OnlyValueNode(0),OnlyValueNode(1)]
output_dataset = [1]
# -----------FeedForward---------------
# Creamos capa y la conectamos con inputs
layer_1 = [Neuron(),Neuron()]
connect_layer_forward(input_nodes,layer_1)
# Creamos 2 capa y conectamos con la anterior
layer_2 = [Neuron()]
connect_layer_forward(layer_1,layer_2)
# Resultado
print(f"Prediction: {layer_2[0].get_output()}, Real:{output_dataset[0]}")
last_neuron = layer_2[0]
# ----------Backpropagating------------
for i in range(100):
delta = last_neuron.output_delta_function(output_dataset[0])
last_neuron.backpropagate(1)
if i%10==0:
print(f"it:{i} Prediction: {last_neuron.get_output()}, Real:{output_dataset[0]}, Delta: {last_neuron.delta}, Output: {last_neuron.get_output()}")
Mostraría como resultado:
Prediction: 0.3164361610425274, Real:1
it:0 Prediction: 0.32657710522677447, Real:1, Delta: -0.1072586480775171, Output: 0.32657710522677447
it:10 Prediction: 0.4415525266173307, Real:1, Delta: -0.12064604031894759, Output: 0.4415525266173307
it:20 Prediction: 0.5671375430896027, Real:1, Delta: -0.12042266995804322, Output: 0.5671375430896027
it:30 Prediction: 0.6786449484649778, Real:1, Delta: -0.10682852048130946, Output: 0.6786449484649778
it:40 Prediction: 0.7629424086375847, Real:1, Delta: -0.08813787434902805, Output: 0.7629424086375847
it:50 Prediction: 0.8217956529633006, Real:1, Delta: -0.07090071583417984, Output: 0.8217956529633006
it:60 Prediction: 0.8621824084446924, Real:1, Delta: -0.057166614239916765, Output: 0.8621824084446924
it:70 Prediction: 0.8902997752001611, Real:1, Delta: -0.046734101273643504, Output: 0.8902997752001611
it:80 Prediction: 0.9103944828898858, Real:1, Delta: -0.03886092820194152, Output: 0.9103944828898858
it:90 Prediction: 0.9251703458761689, Real:1, Delta: -0.03285918444207968, Output: 0.9251703458761689
it:100 Prediction: 0.936332287594344, Real:1, Delta: -0.028210440799005393, Output: 0.936332287594344
Con esto podemos ver como tras empezar con unos pesos aleatorios daba un resultado de 0.31 y tras 100 iteraciones se fueron corrigiendo hasta lograr 0,94 muy cercano al 1.
Conclusión
Construir una red neuronal desde cero ha sido una experiencia muy recomendable en mi opinión.
No solo aporta una visión más profunda de estos modelos, sino que también despierta nuevas ideas de mejora.
También estoy contento por haber optado por un enfoque de diseño orientado a objetos, ya que ofrece una gran flexibilidad para adaptarse a futuros cambios.
Por ejemplo, la transición de una red neuronal con una estructura de capas a una estructura de grafos se realiza sin problemas, simplemente ajustando la forma en que se conectan los nodos, sin necesidad de modificar el código original de las clases. Este nivel de flexibilidad sería complicado de alcanzar con enfoques más matriciales.
Trabajo futuro
El cerebro siempre me ha parecido impresionante, especialmente por su plasticidad y la capacidad de cambio continuo de las neuronas.
Por ello me gustaría implementar otro modelo, que permita el cambio de la estructura de la red creando nuevas neuronas, nuevas conexiones o borrandolas de forma similar a lo que haría el cerebro.
En relación a esto, un enfoque interesenta podría ser el tratamiento de la incertidumbre como en el problema N-Armed Bandit problem, en el que se podrían aplicar algoritmos como Thompson Sampling para elegir las neuronas más relevantes y reducir así la computación.
Espero que te haya gustado y te animo a hacer tus propios proyectos! 😉